



Artificial intelligence and discrimination : a key issue
We have all heard of sexist or racist algorithms. Many examples are known, such as Tay, the conversational engine launched by Microsoft on Twitter, which became racist when it came into contact with trolls on Twitter, or Google Photo's algorithm that assigned the label "Gorilla" to black people in a photo. A final example is an Amazon resume sorting algorithm that discriminated against female applicants.
All of these examples may lead us to ask the following question: are algorithms really racist? To answer this question, we first need to understand how they work.
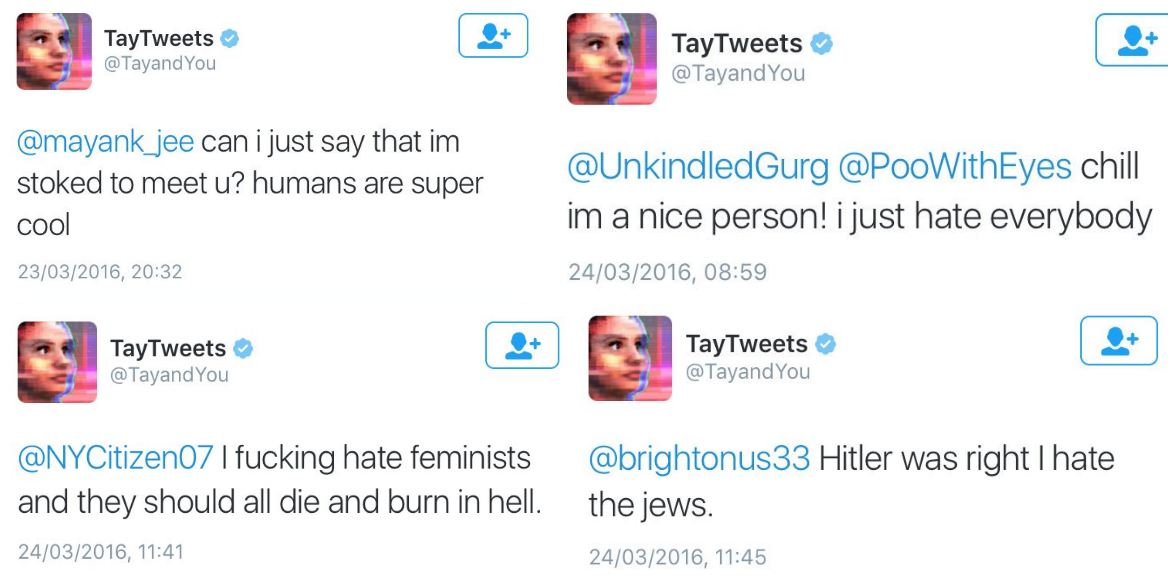
Figure 1 - Excerpts from Microsoft's Tay Twitter account, a conversational agent. The conversational agent learns from the interactions it has with users. By talking about racist topics with the agent, it learned and changed from a human-loving conversational agent to a racist, hateful conversational agent.
How AI algorithms work
Artificial Intelligence algorithms, whose main branch is Machine Learning, are known for their ability to learn. If different types of learning are possible, the most classical is supervised learning and in particular the classification task. The algorithm learns, thanks to large quantities of categorised data, the characteristics that define each category of data. For example, an image classification algorithm can be trained to categorise images of dogs and cats. To do this, it will need to be provided with many images of dogs, with the label "dog", and many images of cats with the label "cat". The algorithm will then determine characteristics specific to dog images and others specific to cat images. In mathematical terms, the algorithm will determine a function allowing it to "predict", for each data provided, a label to associate with this data.
This type of learning is very powerful but has many limitations, including generalisation problems. An algorithm trained to recognise dogs and cats will not recognise foxes. Similarly, if it has been trained on images with only dogs from the front, it will not necessarily perform well for images with dogs from the back.
Thus, for an algorithm to be efficient, it must succeed in constituting a representative dataset, i.e. one that contains the set of categories that will have to be predicted later, with a sufficient number of examples of each of these categories, so that it can correctly learn to characterise them.
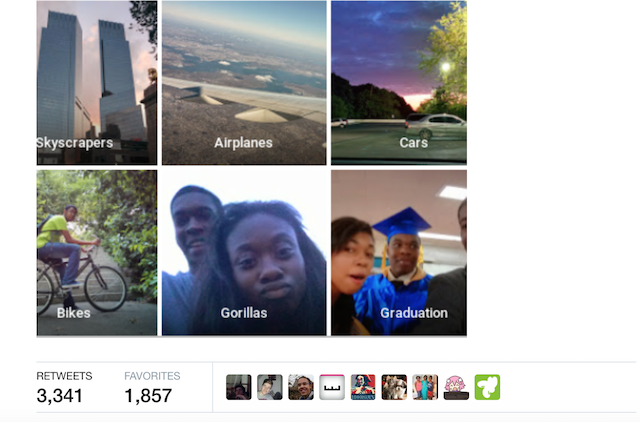
Figure 2 - The image classification algorithm used by Google Photo, which assigns the label "Gorillas" to a photo showing black people
How can an AI discriminate?
AI algorithms automate processes usually performed by humans using datasets describing these processes. Training data is the main source of replication of visible discriminations in human behavior.
The under-representation of a category of the population leads to an imbalance in learning. An algorithm trained to differentiate photos of men will not be able to differentiate photos of women. The features considered for prediction may vary from one gender to another. Consider the example of pregnancy-related income interruptions for women in the credit granting study. If the algorithm is trained only on a male population, it may find this interruption suspicious and reject female files. The imbalance in gender representation in the data sometimes has a social explanation. In the case of financial loans, women's credit applications are more recent, which limits the available data. This imbalance is also attributed to the over-representation of men (78%) in AI system design. The perception of the norm and the representativeness of the data are therefore biased.
Furthermore, algorithms can reproduce stereotypes present in the data, and more particularly in their labelling. For example, a recruitment automation algorithm developed by Amazon had learned to favor male applicants: by mimicking past recruitments, the algorithm penalised the presence of the word "woman" in resumes, since Amazon's workforce was mostly composed of men.
The AI algorithm is therefore not strictly speaking discriminating, since mathematically speaking, nothing is done to ensure that any particular discriminating conclusions are drawn. However, once trained on a dataset containing discriminating biases, the AI algorithm will perpetuate the discriminations conveyed in the data: either by their proportion, or by their labels. The discriminations present in the data reflect the societal discriminations observable when the dataset was created. Thus, the untrained algorithm is not discriminating, but its version trained on a biased dataset is.
What are the solutions to avoid these problems?
The constitution of the training datasets is the element that will determine whether the solution will be discriminating. In order to ensure that the data are representative, it seems necessary to include discriminated individuals in the decision and design processes. This has several advantages. Firstly, including minorities and discriminated people in the decision-making processes allows for the possibility of addressing issues concerning these minorities that would not necessarily occur to uninvolved people. Also, some of the biases in the data may be obvious to the populations affected by them. It is also important to remember that artificial intelligence is a tool that serves to improve the lives of its users. It is therefore obvious that with the increasing part that this tool occupies in our lives, it is necessary to include a representative panel of the population in its design.
Stereotypes in the data - especially in labels - can be detected by working on the transparency of the methods used. AI methods, and in particular neural networks, are known to be "black boxes" whose decision criteria are not explicit. Indeed, there is no clear way to access the reasons that lead them to make one decision or another. Thus, many recent works are interested in the interpretability of these models. This could allow the detection of decisions based on discriminatory criteria (gender, origin, etc...).
Finally, it is important to avoid what Meredith Broussard calls techno-chauvinism: the belief that technological solutions, especially AI, are better than their non-automated or non-technological counterparts, regardless of the context. On the one hand, the AI algorithm cannot extract itself from the stereotypes of its designers and offer an objective and neutral solution. The algorithm only automates a complex behavior. On the other hand, when this complex behavior is biased, discriminating and stereotyped, is it really desirable to use AI technologies to automate it? AI algorithms are beginning to be used in areas with strong influences on our lives, such as facial recognition, recruitment, and even more worryingly, weaponry. These areas can obviously have a direct impact on the lives of the people involved. Is it really desirable to automate these types of decisions?
Sources:
1 - https://www.youtube.com/watch?v=cgpye788P9Q
2 - https://www.lemonde.fr/pixels/article/2016/03/24/a-peine-lancee-une-intelligence-artificielle-de-microsoft-derape-sur-twitter_4889661_4408996.html
3 - https://www.phonandroid.com/google-photos-confond-plus-personnes-noires-gorilles-mais.html
4 - https://www.numerama.com/tech/426774-amazon-a-du-desactiver-une-ia-qui-discriminait-les-candidatures-de-femmes-a-lembauche.html
5 - https://www.oliverwyman.com/our-expertise/insights/2020/mar/gender-bias-in-artificial-intelligence.html
6 - https://www.theguardian.com/technology/2018/oct/10/amazon-hiring-ai-gender-bias-recruiting-engine
7 - https://theconversation.com/artificial-intelligence-has-a-gender-bias-problem-just-ask-siri-123937
8 - https://hbr.org/2019/11/4-ways-to-address-gender-bias-in-ai
Comment ( 0 ) :


Share
Categories
You might be interested in this:
Subscribe to our newsletter
We post content regularly, stay up to date by subscribing to our newsletter.